
Menu
Why Custom CUDA Kernels via PyBind11 Can Outperform Pure PyTorch in LLM Fine-Tuning

Training and fine-tuning large language models can require thousands of GPU hours. At this scale, even small inefficiencies in kernel execution translate into meaningful increases in cost and runtime.
Neural Nova focuses on improving the efficiency of AI training and inference workloads by automatically automatically analyzes model execution graphs and generating optimized CUDA kernels to reduce GPU runtime required to train and run large-scale models.
Modern machine learning frameworks such as PyTorch and Hugging Face Transformers have dramatically simplified model development. With only a few lines of code, developers can load multi-billion-parameter models and run distributed training workloads across GPUs.
However, as workloads scale to billions of tokens and thousands of GPU hours, the default framework stack often leaves measurable performance on the table.
Many kernels used during transformer training are designed to support a wide range of workloads rather than the specific compute and memory patterns common in large language models. While this generality improves usability, it can introduce inefficiencies in high-throughput training environments.
Toward Automated Kernel Optimization
Writing highly optimized CUDA kernels manually is time-consuming and requires deep GPU programming expertise. Neural Nova addresses this challenge through the Nova AI Engine, which automates the kernel optimization process.
Nova analyzes model execution graphs, profiles GPU kernel behavior, generates candidate CUDA implementations, validates numerical correctness, and benchmarks performance against baseline implementations. The best-performing kernels are then automatically integrated back into the training pipeline, allowing models to benefit from specialized GPU optimizations without requiring developers to write custom kernels.
In this article, we illustrate this process using the Qwen3-4B model as a case study.
The LLM Training Execution Stack
Most large language model training pipelines follow a layered execution stack:
At the Python level, frameworks provide high-level abstractions for defining models and training loops. These abstractions ultimately map to ATen operators, which form the core tensor operation library used internally by PyTorch.
ATen operators dispatch to CUDA kernels depending on tensor type and device.
This architecture provides flexibility across:
tensor layouts
hardware backends
mixed-precision datatypes
broadcasting semantics
While this abstraction makes frameworks extremely productive, it can introduce overhead when executing large-scale transformer workloads.
Where Framework Kernels Lose Performance
Framework kernels must remain general enough to support many workloads. This design constraint can introduce inefficiencies when running large transformer models.
Multiple Kernel Launches
Some operations are implemented as sequences of smaller kernels. For example, a normalization operation may involve:
computing statistics
computing normalized values
applying scaling parameters
Each stage may trigger its own CUDA kernel launch.
While the cost of a single launch is small, the overhead becomes significant when the same operation is executed millions of times during training.
Excessive Global Memory Traffic
Generic implementations may also move tensors through global memory multiple times.
For example, separate passes may be used to:
compute statistics
apply normalization
apply scaling
In memory-bound workloads, these additional passes increase global memory traffic and reduce effective throughput.
General-Purpose Operator Logic
Framework operators must support a wide range of tensor layouts, datatypes, and broadcasting rules. As a result, kernels often include conditional logic and pointer arithmetic to handle many possible input configurations. For workloads with predictable tensor shapes—such as transformer training—this additional generality can introduce unnecessary overhead.
Why Specialized CUDA Kernels Help
When tensor shapes and execution patterns are known in advance, kernels can be written specifically for those patterns.
This allows several optimizations:
reducing the number of kernel launches
minimizing global memory passes
improving memory access patterns
increasing arithmetic intensity within each kernel
By tailoring kernels to the structure of transformer models, it is often possible to improve GPU utilization and reduce training step latency.
Identifying Optimization Opportunities
We need to investigate the overall architectural layer of QWEN3 to identify the target operator for optimization. A simplified view of the transformer block used by Qwen3 is shown below:
This structure highlights the sequence of operations executed within each transformer layer and helps identify operators that appear repeatedly throughout the model. We use Nova AI Engine to automatically profile the training workload to examine GPU utilization and estimate potential performance gains for the most frequently executed kernels.
For this article, we focus on forward-pass acceleration within a fine-tuning workload. Among the operators in the transformer block, RMSNorm is a particularly interesting candidate for optimization. It appears multiple times per layer and is executed repeatedly across the model during both training and inference.
RMSNorm Baseline Implementation
RMSNorm normalizes hidden states by scaling each element with the reciprocal square root of the mean squared activations, followed by a learnable per-channel weight multiplication. Formally:
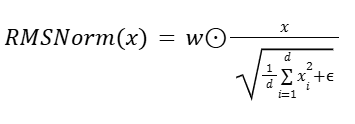
Where:
x= (x1, ... , xd): input hidden state
d: hidden dimension
ϵ : small constant for numerical stability
w E Rd: learnable per-channel (per-feature) weight
⊙: element-wise multiplication
Below is the reference PyTorch implementation of RMSNorm used in the Qwen-3 model.
Baseline Runtime Analysis
To understand baseline runtime behavior, we analyze kernel traces captured with Perfetto during fine-tuning. These traces reveal that RMSNorm is invoked twice per transformer block and accounts for roughly 8.6% of total forward-pass time (3.6 ms out of 310 ms). Although not the largest operator, its frequent execution across layers makes it a strong candidate for optimization.
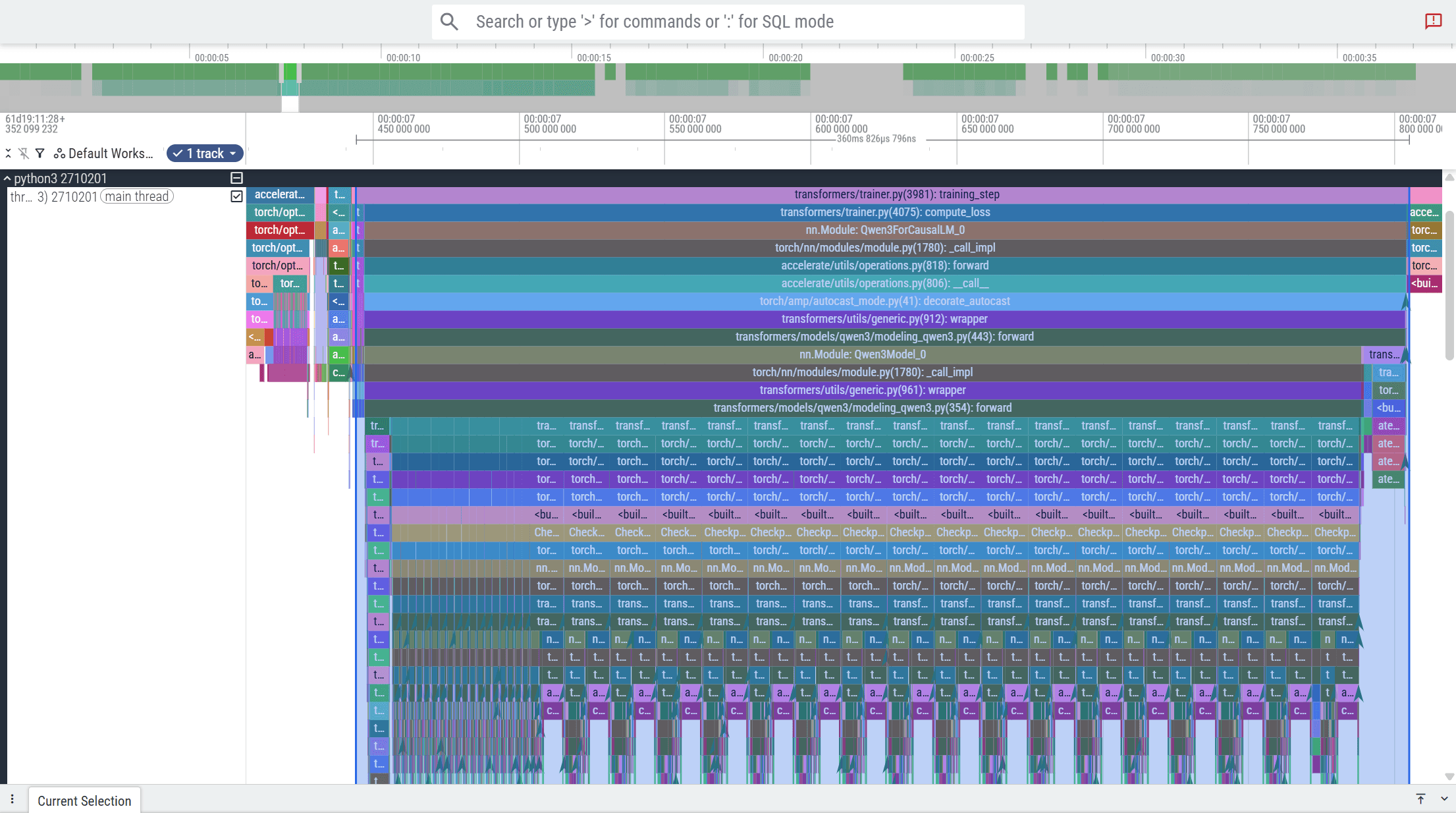
From the trace, we observe that RMSNorm is invoked twice during the forward pass of each transformer block.
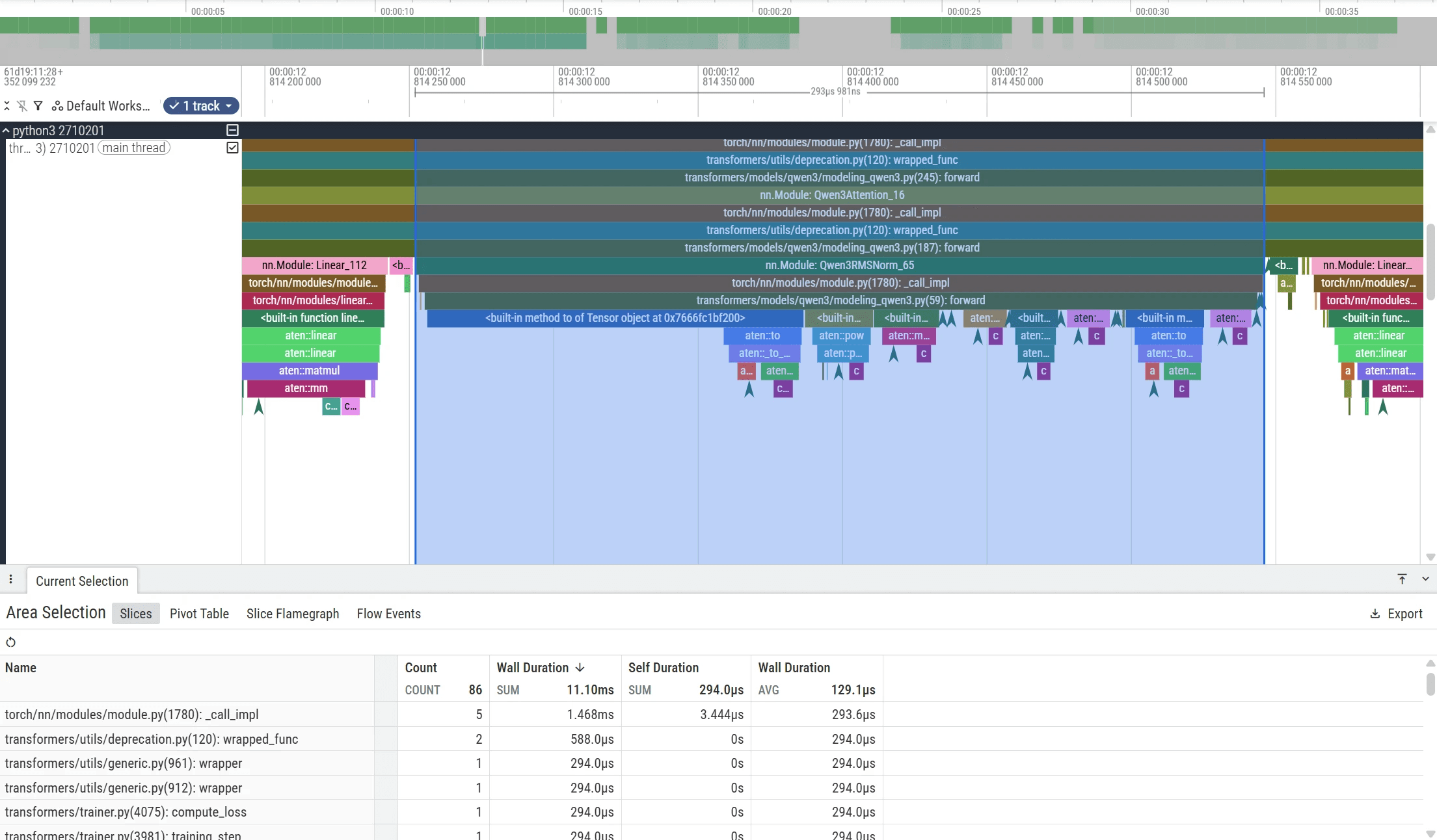
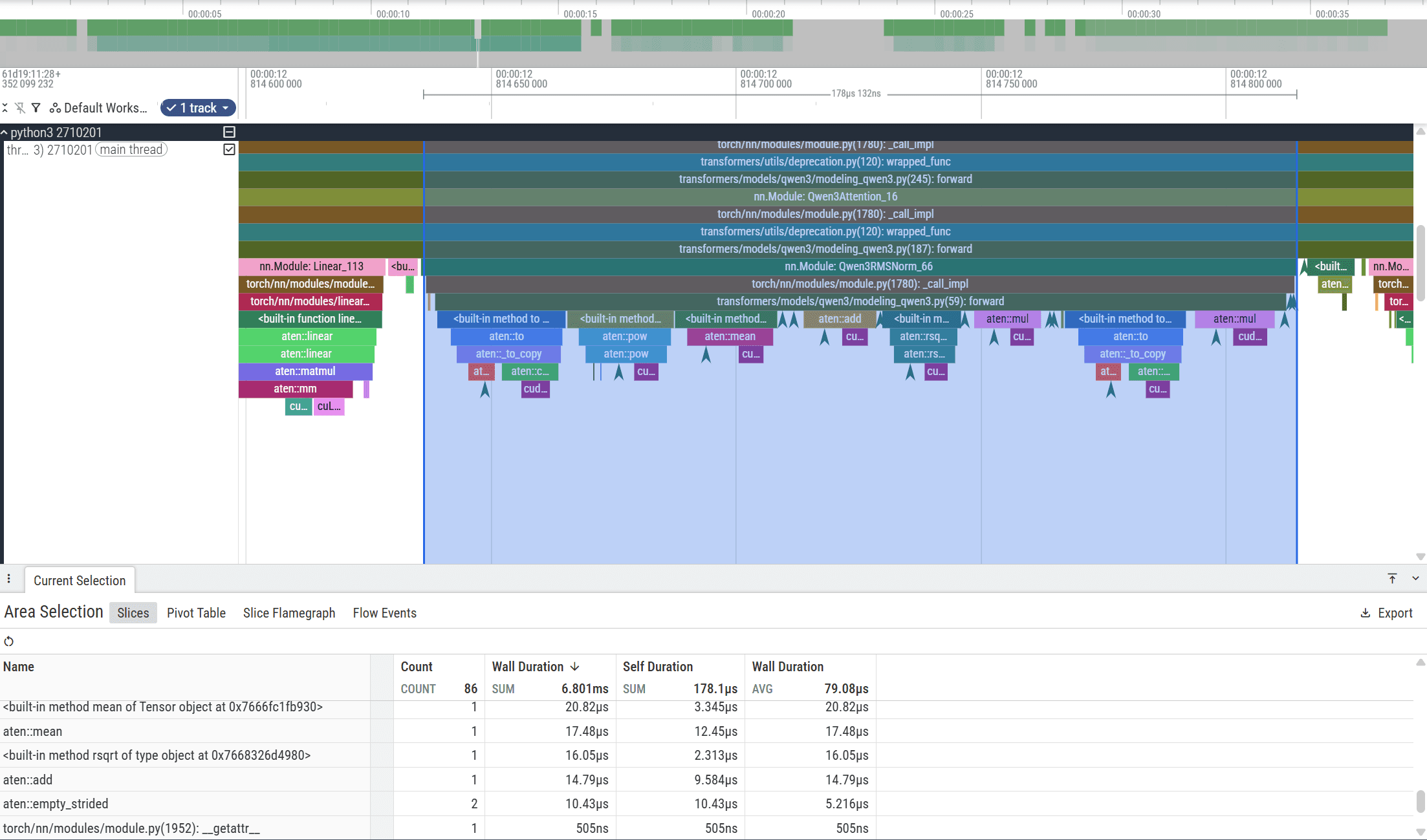
Zooming into the trace shows that the baseline RMSNorm implementation consists of multiple ATen operators—including power, multiplication, addition, and reduction—which together take approximately 293 µs and 178 µs before the subsequent linear projection. Because these steps are executed as separate kernels, they introduce multiple kernel launches and repeated global memory passes.
This makes RMSNorm a strong candidate for kernel fusion. By combining these operations into a single CUDA kernel, we can reduce launch overhead and improve GPU utilization.
Automatic Kernel Generation with Nova AI Engine
For RMSNorm, the Nova AI Engine analyzes the baseline PyTorch implementation and identifies the sequence of ATen operators involved in the computation. These operators are mapped to their underlying CUDA kernels and profiled using hardware metrics from Nsight Compute.
Based on this profiling data, Nova generates candidate CUDA kernels designed to improve GPU utilization and reduce memory traffic. Each candidate kernel is automatically:
compiled and executed
validated for numerical correctness
benchmarked against the baseline implementation
The highest-performing kernel is then selected and integrated back into the training pipeline.
Optimized CUDA Kernels Snippet
Optimization Strategy
The optimized RMSNorm kernel applies the following techniques:
Thread-block–strided reduction: Instead of assigning a single element per thread, elements are processed using a block-level stride, enabling parallel accumulation of squared values across threads within a block.
Shared-memory reduction: Intermediate reduction results are stored in shared memory, reducing global memory traffic and improving utilization of the GPU memory hierarchy.
Coalesced memory access: The access pattern
for (int i = tid; i < hidden_size; i += BlockSize)ensures that threads within a warp access contiguous memory locations, resulting in coalesced global memory accesses for typical hidden sizes.Operator fusion: Variance computation, normalization, and weight scaling are fused into a single kernel launch, eliminating intermediate tensors and reducing kernel launch overhead.
Block-level reuse of normalization factor: The normalization factor is computed once per row and stored in shared memory, allowing all threads within the block to reuse it without redundant computation.
Accumulation is performed in FP32 to preserve numerical stability, while synchronization is limited to the minimum required for correctness.
Correctness and Microbenchmark Evaluation
We next evaluate the correctness and performance of the optimized RMSNorm kernel against the baseline implementation.
Both versions are tested using identical input tensors with floating-point tolerances to verify numerical accuracy. Performance measurements are averaged across 1,000 benchmark iterations to minimize measurement noise.
Result:
The optimized kernel significantly outperforms the PyTorch operator in both native and torch.compile modes while maintaining similar power consumption. The speedup comes from eliminating framework overhead, improving memory access patterns, and executing the entire operation in a single specialized kernel. In contrast, torch.compile is more effective for large graph fusion and may offer limited benefits for small, memory-bound kernels.
After validating correctness and benchmarking the optimized kernel, the next step is integrating a custom RMSNorm backward pass into the Qwen3 model so the operator can be used during training. The optimized backward implementation will be covered in a future article on end-to-end model optimization. In this post, we focus on forward-pass acceleration to demonstrate kernel customization using Pybind11.
Integrating the Optimized Kernel into Fine-Tuning
We integrate the new RMS Norm forward pass on the fine-tune process on QWEN3 models. We will use real-world data from Nemotron-Post-Training-Dataset-v2, focusing on mathematics and programming tasks. To utilize our optimized RMSNorm, we create a new class from Python
This wrapper allows the Qwen3 model to call the optimized CUDA implementation through a custom autograd function.
Next, we modify the main Qwen3 model definition so that the optimized RMSNorm operator is used inside the attention module:
With this change, the Qwen3 attention block uses the optimized RMSNorm implementation for both query and key normalization. Finally, we expose the CUDA kernel through Pybind11 on the C++ side. At this stage, we initialize the kernel launch configuration and bind the input tensors so that the Python layer can call the optimized implementation directly.
To make the optimized CUDA implementation accessible from Python, we expose the kernel through Pybind11 bindings on the C++ side. This layer connects the PyTorch module to the underlying CUDA kernel. Within the extension, we configure kernel launch parameters—such as grid size, block size, and shared memory—based on the input tensor shape, ensuring tensors are contiguous for efficient execution.
This setup allows the Python-level Qwen3RMSNormFunction to invoke the optimized kernel directly while remaining fully compatible with PyTorch’s tensor interface, enabling seamless integration into the Qwen3 training pipeline.
Next, we set the fine-tuning configurations and datasets to measure the forward pass speedups.
Configurations :
Model: Qwen/Qwen3-4B-Instruct-2507
Dataset: nvidia/Nemotron-Post-Training-Dataset-v2 (split: math,code)
Max Train Samples: 1000
Batch Size: 2 (per device)
Gradient Accumulation: 2
Max Length: 8192
Learning Rate: 2e-5
Precision: bfloat16
Hardware: NVIDIA H100 GPU
Software :
CUDA : 13.0
Pytorch : 2.10
Transformers : 4.57
To verify the performance improvements under a realistic workload, we again measure forward-pass runtime using Perfetto traces collected during the fine-tuning process. At the operator level, the optimized RMSNorm kernel maintains approximately 5× speedup compared to the baseline implementation when executed within the fine-tuning workload. We then examine the impact on the overall forward-pass runtime. After integrating the optimized kernel generated by the Nova AI Engine, the total forward-pass latency is significantly reduced:
Metric | Baseline (ms) | Neural Nova (ms) |
|---|---|---|
Forward pass latency | 360 | 194 |
RMSNorm runtime | 31.49 | 9.66 |
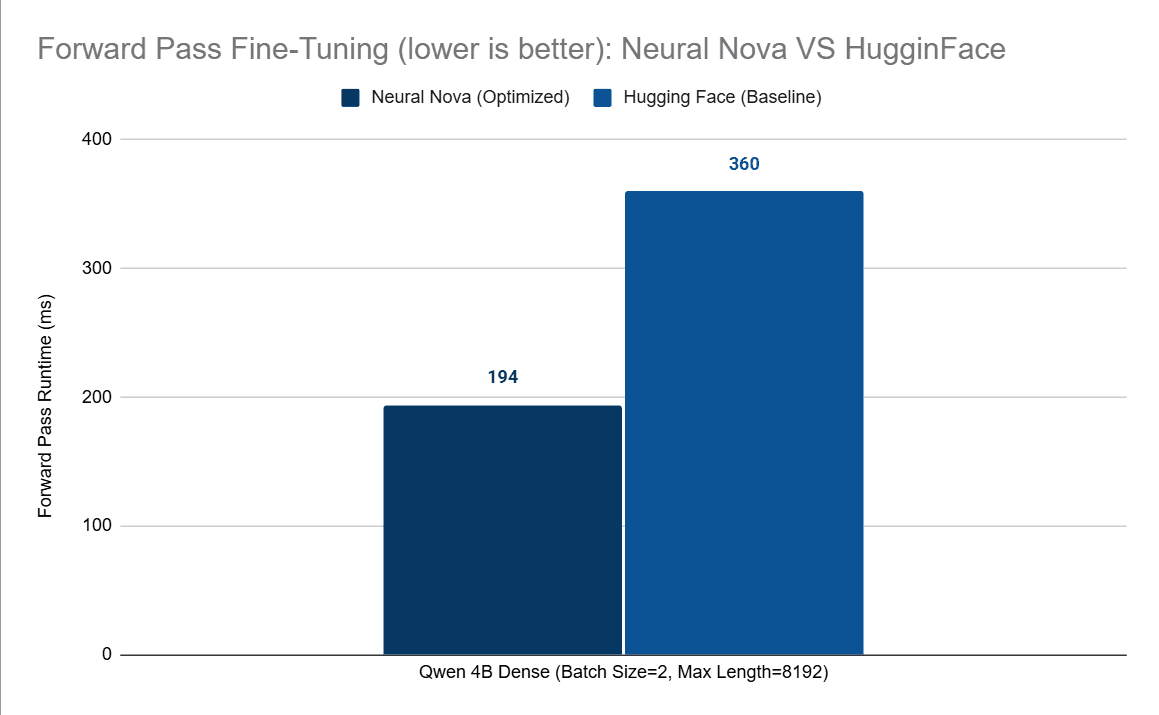
This represents more than a 50% reduction in forward-pass latency within the fine-tuning. Although RMSNorm accounts for roughly 8.6% of forward-pass runtime individually, it is invoked repeatedly across transformer layers. Kernel fusion eliminates multiple launches and memory passes per invocation, allowing the performance improvements to compound across the entire forward pass.
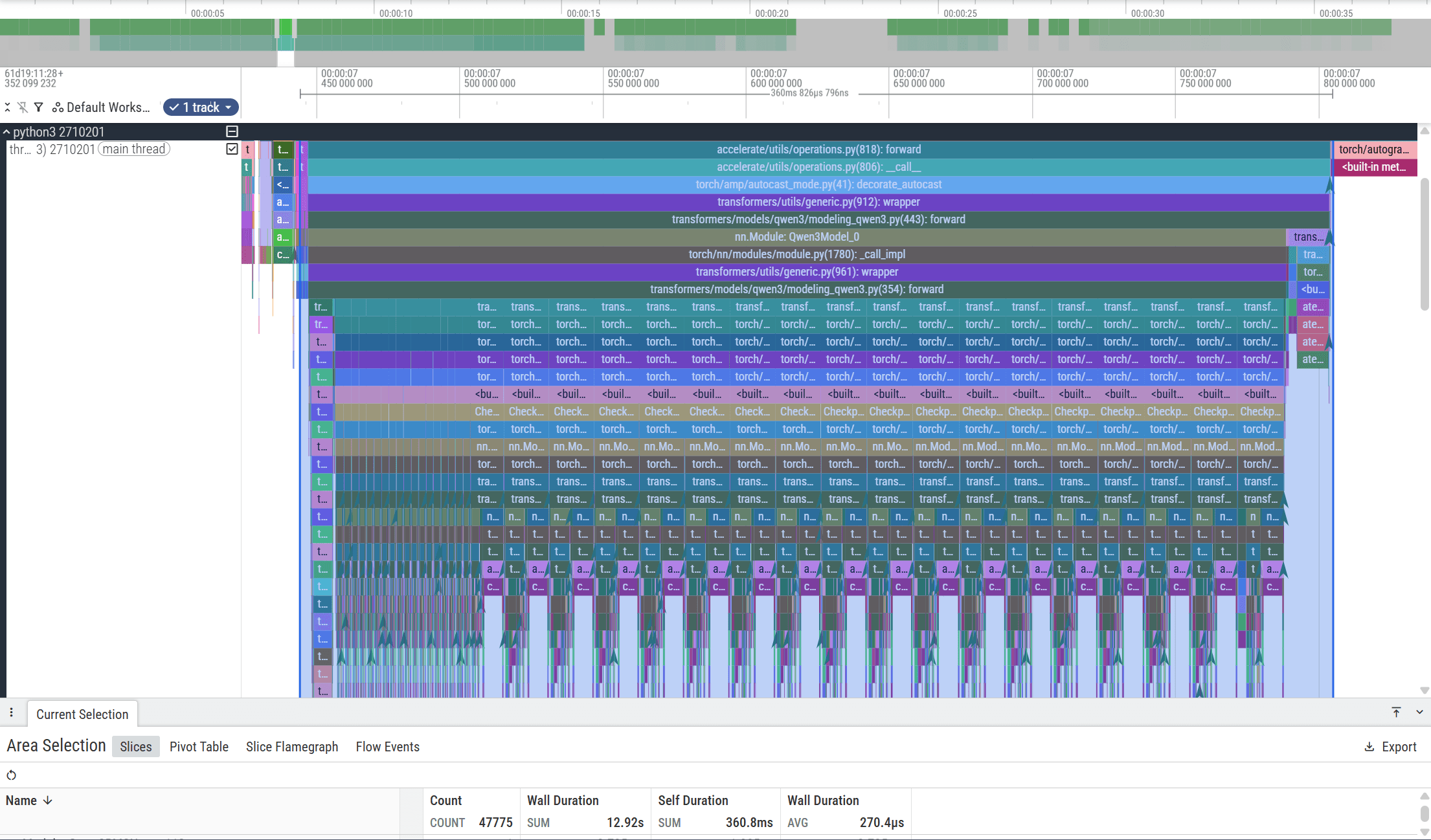
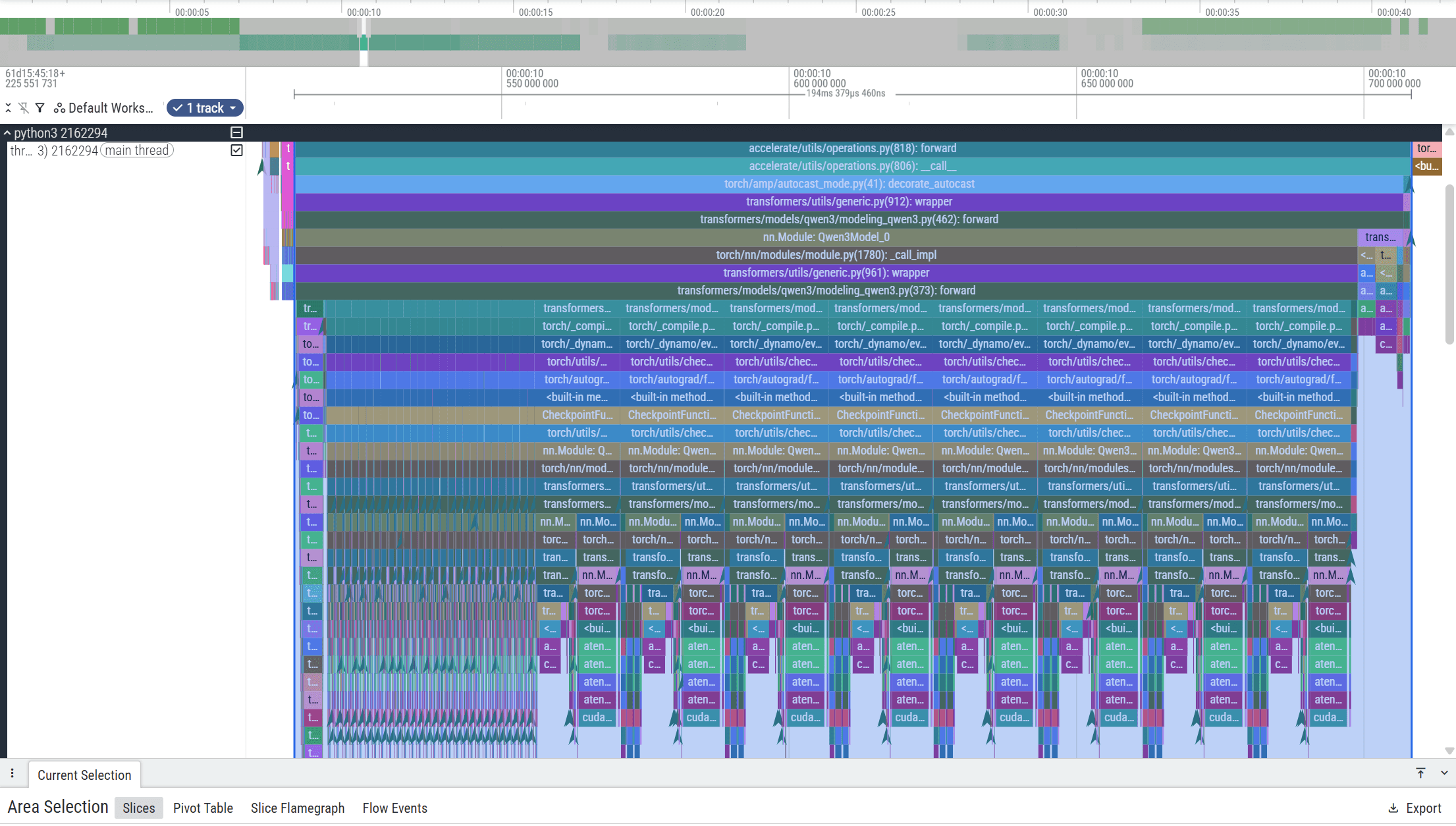
The Perfetto traces below illustrate the difference between the baseline execution and the optimized version.
Baseline:
Optimized Version:
Summary
In this article, we demonstrated how the Nova AI Engine automatically optimizes GPU kernels for large language model workloads. Using Qwen3-4B as a case study, Nova identified RMSNorm as a bottleneck, generated a fused CUDA kernel, and achieved ~5× operator-level speedup, reducing RMSNorm runtime from 31.49 ms to 9.66 ms and lowering forward-pass latency from 360 ms to 194 ms during fine-tuning.
These results illustrate how operator-level optimizations can compound across transformer layers. Instead of requiring engineers to manually design CUDA kernels, Nova automatically analyzes model execution graphs, profiles GPU behavior, generates optimized kernels, and integrates them into the training pipeline.
This article focused on forward-pass acceleration using Pybind11-based kernels. Future work will introduce the optimized backward pass and demonstrate full end-to-end training optimization.
Neural Nova’s vision is to build an intelligent execution layer for AI workloads, allowing models to automatically adapt computation to the underlying hardware without requiring low-level GPU optimization.