
Menu
How Nova AI Engine Optimizes AI Workloads End-to-End

Introduction
In our previous post, we showed how Nova AI Engine can automatically optimize individual bottlenecks like RMSNorm. But in practice, optimizing a single operator is not the hard part—the real challenge is everything around it.
Today, performance optimization is still largely a manual process. Engineers profile models, inspect traces, identify slow operators, experiment with kernel implementations, tune launch configurations, validate correctness, benchmark results, and repeat this process across multiple components. Each step requires deep expertise in GPU architecture, memory behavior, and low-level programming. Even then, improvements are often incremental, non-transferable, and difficult to maintain as models evolve. Worse, optimization does not happen in isolation. Fixing one bottleneck often exposes another. A kernel that performs well under one workload may degrade under different shapes or batch sizes. What should be a systematic process becomes an iterative, fragmented cycle of trial and error.
This is the problem Nova AI Engine is designed to solve. Instead of treating optimization as a series of manual interventions, Neural Nova automates the entire workflow—from analyzing model execution and identifying bottlenecks to generating, evaluating, and integrating optimized GPU kernels. At the core is a hardware-driven feedback loop that continuously searches for better implementations based on real runtime signals.
In this post, we walk through how Nova AI Engine operates end-to-end, and how it replaces a traditionally manual process with a fully automated system.
Nova AI Engine End-to-End Workflow
Rather than treating optimization as a sequence of manual steps, Nova AI Engine organizes the process into a structured, end-to-end workflow that operates directly on model execution.
At a high level, Neural Nova takes a model defined in PyTorch or similar frameworks and transforms it into an optimized execution pipeline through a series of stages: parsing the computation graph, identifying performance-critical regions, generating specialized kernels, and integrating them back into the model. What distinguishes this workflow is that these stages are not independent. Kernel generation, evaluation, and integration are tightly coupled through a continuous feedback loop driven by real hardware signals. Instead of optimizing operators in isolation, Neural Nova evaluates performance in context—taking into account memory behavior, execution dependencies, and runtime characteristics.
This allows the system to move beyond static optimization and into dynamic search, where multiple kernel candidates are generated and refined based on actual execution performance. The diagram below illustrates how these components interact within Nova AI Engine.
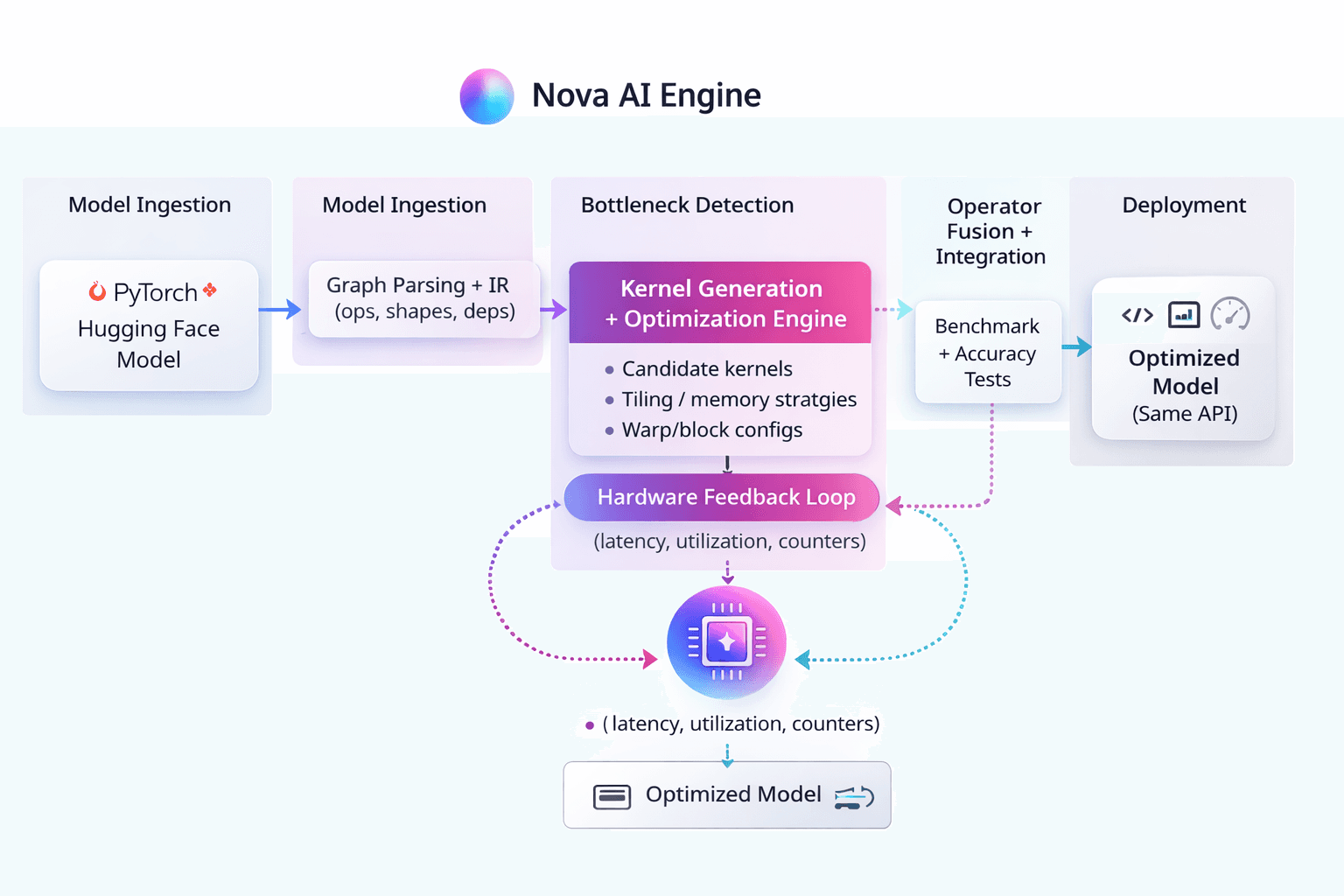
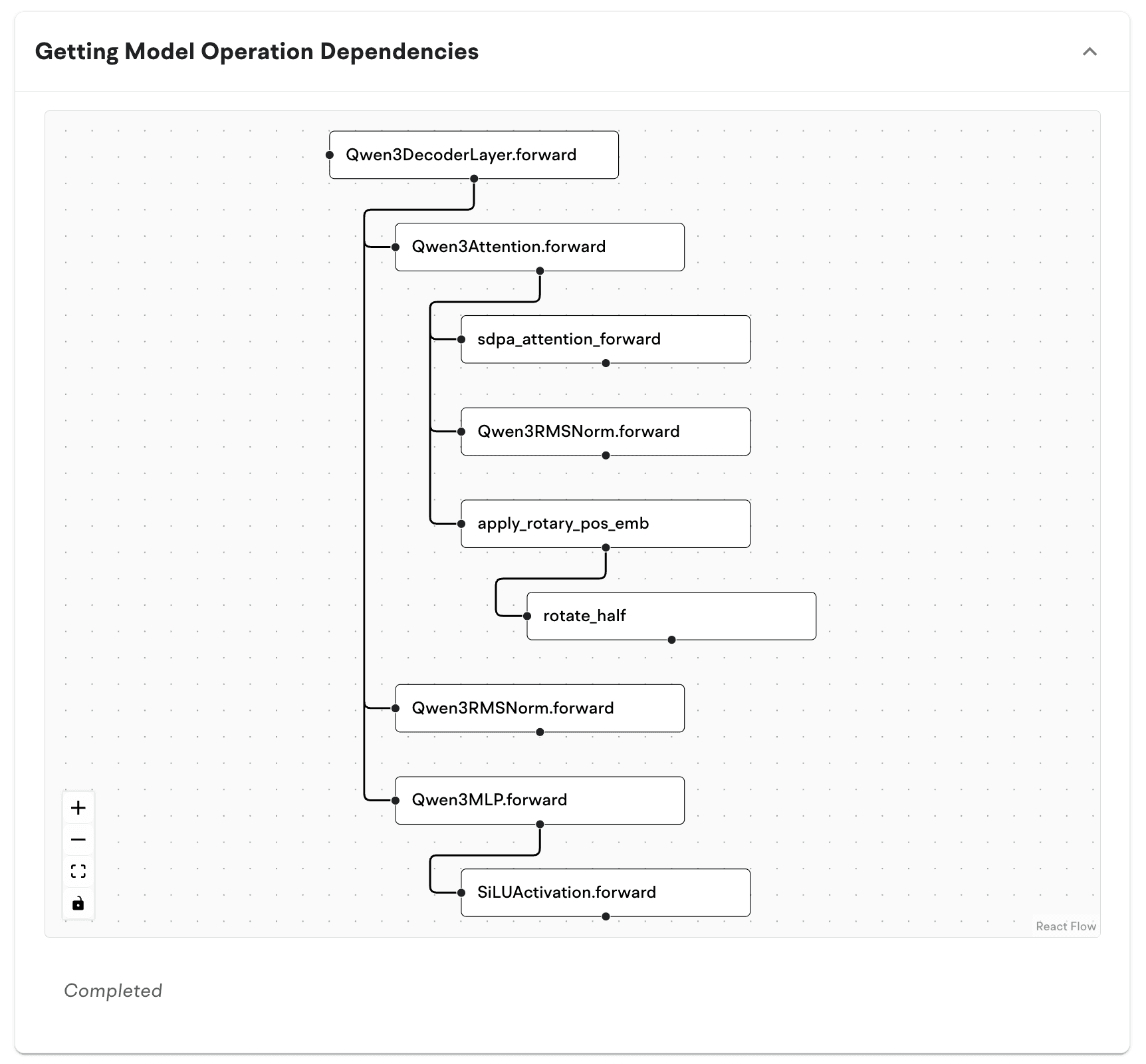
Step 1: Model Ingestion and Graph Parsing
The workflow begins with ingesting a model defined in PyTorch or compatible frameworks. Rather than operating at the source code level, Neural Nova works on the model’s execution structure. Neural Nova extracts the computation graph along with operator-level details such as tensor shapes, data types, and dependencies between operations. This representation captures how data flows through the model during execution, forming the foundation for all subsequent optimization steps. At this stage, no assumptions are made about which parts of the model should be optimized. Instead, Neural Nova builds a complete view of the workload, enabling later stages to reason about performance in a global context rather than at the level of individual operators.
Step 2: Bottleneck Detection
With the execution graph in place, Neural Nova profiles the model to identify performance-critical regions. This goes beyond simply measuring which operators take the longest time. Neural Nova analyzes multiple signals, including execution latency, memory bandwidth utilization, and GPU occupancy, to determine why a given operator becomes a bottleneck.
In many cases, inefficiencies are not due to compute limitations but memory access patterns or suboptimal kernel configurations. By combining runtime profiling with structural information from the graph, Neural Nova isolates the operators where optimization will have the highest impact ensuring that optimization efforts are focused where they matter most.
Step 3: Kernel Generation
Once bottlenecks are identified, Neural Nova generates candidate kernels tailored to the specific operator and workload characteristics. Instead of relying on predefined implementations, Neural Nova explores a space of possible execution strategies. This includes variations in tiling schemes, memory layouts, parallelization strategies, and thread/block configurations. Each candidate represents a different way of mapping the same computation onto GPU hardware. The goal at this stage is not to immediately find the optimal kernel, but to construct a diverse set of viable implementations that can be evaluated and refined in the next phase.
Step 4: Hardware-Driven Optimization Loop
This is the core of Nova AI Engine. Each candidate kernel is executed on real hardware and evaluated using runtime metrics such as latency, memory throughput, and utilization. These signals are fed back into the system to guide the search for better implementations.
Rather than relying on static heuristics, Neural Nova continuously compares candidate kernels, identifies which strategies perform well, and refines future generations accordingly. Poor-performing variants are discarded, while promising ones are further optimized. This creates a closed-loop system where kernel performance is learned directly from hardware behavior. Over successive iterations, the system converges toward implementations that are well-matched to both the workload and the underlying GPU architecture.
For example, operators such as normalization layers often appear lightweight at the model level but become memory-bound in practice. Through this optimization loop, Neural Nova restructures these operators into fused implementations that significantly reduce memory traffic and improve utilization—without manual kernel design.
Step 5: Operator Fusion and Integration
After optimized kernels are identified, Neural Nova integrates them back into the model execution pipeline. This often involves fusing multiple operators into a single kernel to reduce memory movement and eliminate unnecessary intermediate states. For example, normalization, scaling, and residual operations can be combined into a unified implementation.
Neural Nova ensures that these transformations preserve correctness while improving performance. The optimized kernels replace the original operators transparently, without requiring changes to the model code.
Step 6: Validation and Deployment
Before deployment, Neural Nova validates both correctness and performance. The optimized model is tested against the original implementation to ensure numerical consistency. At the same time, end-to-end benchmarks are run to confirm that local kernel improvements translate into real performance gains at the system level. Once validated, the optimized execution is deployed back into the user’s environment, maintaining the same interface and behavior as the original model.
Results
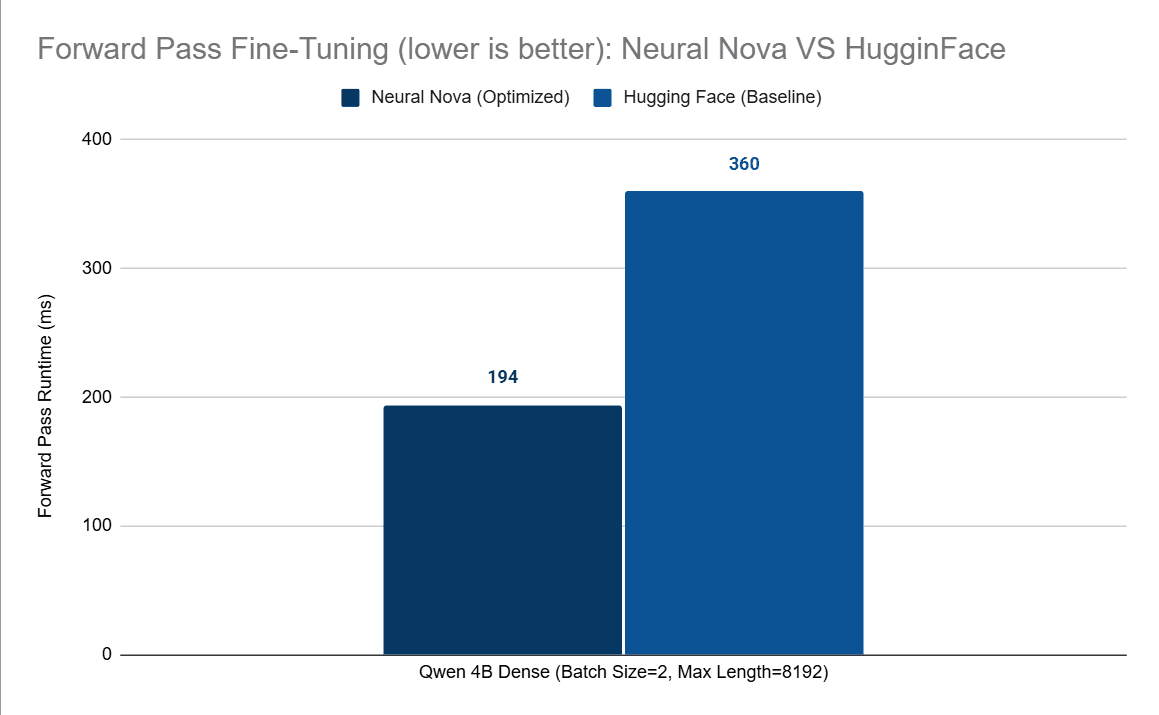
In practice, Neural Nova’s hardware-driven optimization loop translates directly into measurable performance gains at both the operator and model level.
In our previous post where we optimized RMSNorm operation from QWEN3 4B model from Hugging Face using Pytorch as a baseline, Neural Nova achieved:
~5× speedup at the operator level, driven by kernel fusion and improved latency hiding using shared memory
~up to ~50% forward-pass latency reduction in configurations where memory-bound operators dominate execution
These improvements are not isolated. Operators such as normalization, attention, and tensor transformations appear repeatedly across modern architectures. As a result, even modest kernel-level gains compound into meaningful system-level improvements.
More importantly, these results are achieved without manual kernel tuning. Neural Nova automatically generates, evaluates, and refines implementations based on real hardware signals, enabling consistent performance improvements across different models and workloads. This demonstrates a key shift: performance optimization is no longer limited by manual effort or expert intuition, but can be systematically discovered and improved through automated search.
From Optimization to Performance Ownership
Traditional optimization treats performance as a one-time effort—engineers tune kernels, measure improvements, and move on. But as models evolve and workloads change, these optimizations often degrade or become obsolete.
Nova AI Engine takes a different approach.
By continuously evaluating and refining execution based on real hardware behavior, Neural Nova transforms optimization into an ongoing, system-level capability rather than a manual task. Instead of relying on static implementations, performance becomes adaptive—improving as the system observes more execution patterns and workload variations. This shifts performance from something that is engineered once to something that is maintained and improved over time. The result is not just faster kernels, but a new layer of infrastructure where performance is automatically managed, validated, and sustained.