Menu
Achieving 5× End-to-End Fine-Tuning Speedup on Qwen-3 with the Nova AI Engine
Feb 18, 2026

Neural Nova is an optimization and performance ownership platform that systematically improves and maintains model performance without requiring manual kernel tuning or architecture-specific rewrites. It operates directly on model operator graphs to identify performance-critical operators and generate functionally equivalent, hardware-efficient CUDA kernels.
Neural Nova preserves model architecture, training logic, and numerical semantics, while eliminating inefficiencies introduced by framework abstractions and generic operator implementations. By optimizing at the operator level, it remains architecture-agnostic yet captures low-level performance opportunities beyond the reach of graph-level compilers.
Existing approaches—manual kernel tuning, specialized libraries, and graph-level compilers—either do not scale across models and hardware or fail to optimize memory-bound and synchronization-heavy operators. Neural Nova fills this gap by operating at the operator level, generating hardware-aware CUDA kernels tailored to each operator’s access patterns and numerical constraints, delivering consistent speedups while preserving correctness and PyTorch compatibility.
This post demonstrates its capabilities by optimizing an end-to-end fine-tuning workload through operator-level analysis, generation of functionally equivalent optimized kernels, and numerical correctness validation.
The experiments focus on the Qwen-3 4B model running on a single GPU, using a Transformers stack. The scope is intentionally constrained to fine-tuning workloads to isolate performance behavior and optimization effects; model architecture, training logic, and numerical semantics remain unchanged.
The transformer model codebase is first processed by Nova Parsing, which extracts the sequence of operator units eligible for optimization. For each identified operator, we measure baseline performance at both the operator level and the end-to-end forward-pass level to establish reference metrics.
In the Qwen-3 model, execution we primarily focus on are three operators: rotate_half, SiLU activation, and RMSNorm.
Each identified operator is passed to the Neural Nova AI Engine, which generates CUDA kernel implementations while applying internally developed optimization techniques. All generated kernels undergo validations mentioned before being composed back into the optimized model.
We begin with RMSNorm, which normalizes hidden states by scaling each element with the reciprocal square root of the mean squared activations, followed by a per-channel weight multiplication. It is described as follows:
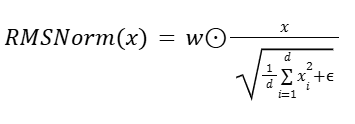
Where:
x= (x1, ... , xd): input hidden state
d: hidden dimension
ϵ : small constant for numerical stability
w E Rd: learnable per-channel (per-feature) weight
⊙: element-wise multiplication
Below is the reference PyTorch implementation of RMSNorm used in the Qwen-3 model.
Pytorch Operators
Optimization Strategy
The optimized RMSNorm kernel applies the following techniques:
Thread-block–strided reduction: Instead of assigning a single element per thread, elements are processed using a block-level stride, enabling parallel accumulation of squared values across threads within a block.
Shared-memory reduction: Intermediate reduction results are stored in shared memory, reducing global memory traffic and improving utilization of the GPU memory hierarchy.
Coalesced memory access: The access pattern
for (int i = tid; i < hidden_size; i += BlockSize)ensures that threads within a warp access contiguous memory locations, resulting in coalesced global memory accesses for typical hidden sizes.Operator fusion: Variance computation, normalization, and weight scaling are fused into a single kernel launch, eliminating intermediate tensors and reducing kernel launch overhead.
Block-level reuse of normalization factor: The normalization factor is computed once per row and stored in shared memory, allowing all threads within the block to reuse it without redundant computation.
Accumulation is performed in FP32 to preserve numerical stability, while synchronization is limited to the minimum required for correctness.
Optimized CUDA Kernels Snippet
The second operator is Rotate Half, a tensor transformation used in rotary positional embeddings (RoPE) that applies a 90-degree rotation within 2D subspaces of the last (hidden) dimension. The operation is inherently memory-bound, as each element involves minimal arithmetic relative to the cost of global memory accesses; consequently, performance is primarily limited by memory bandwidth, and optimizations focus on maximizing memory efficiency through coalesced accesses, reduced instruction overhead, and elimination of intermediate buffers.
The optimized Rotate Half kernel applies the following techniques:
Single-pass elementwise transformation: The rotation and sign inversion are performed in a single kernel pass, avoiding intermediate tensors and additional memory reads associated with slicing and concatenation in the PyTorch implementation.
Linearized indexing over contiguous memory: The kernel operates over a flattened view of the input tensor and uses modulo indexing to map elements to their position within the hidden dimension, enabling a simple and efficient mapping from input to output.
Coalesced global memory access: Threads process consecutive elements in the flattened tensor, resulting in coalesced reads and writes for typical hidden dimensions and contiguous layouts.
Grid-stride loop for scalability: A grid-stride loop is used to cover the full tensor, allowing the kernel to scale efficiently across different tensor sizes and GPU configurations.
Minimal synchronization and control flow: The kernel contains no shared memory usage or inter-thread synchronization, keeping execution lightweight and maximizing occupancy for this memory-bound operation.
Pytorch Operator:
CUDA Optimized Kernel
The 3rd kernel our Nova AI Engine looks into is the Silu Activation function. The Sliu is expressed as:
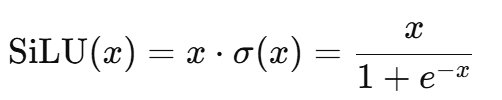
SILU Pytorch operator
SILU CUDA Optimized Kernel
While this kernel incurs minimal computation compared to previous kernels, we can capture optimization applied to this kernel as follows:
Single fused elementwise kernel
Computes x * sigmoid(x) in one kernel launch
Avoids intermediate tensors and extra memory traffic
Contiguous memory enforcement
input.contiguous() guarantees linear, coalesced global memory accesses
Explicit kernel launch control
Fixed BlockSize = 256 chosen for good occupancy on majority of GPUs
Simple 1D grid mapping → minimal indexing overhead
Compile-time specialization
BlockSize as a template parameter enables better register allocation and scheduling
Separate kernel instantiations per data type (float, half, bfloat16)
FP32 math for low-precision inputs
Casts half / bfloat16 to float for sigmoid computation
Improves numerical stability vs pure low-precision math
After optimizing the kernels, we integrated them back into the PyTorch model as custom operators using Pybind11 and Python bindings. We then validated functional correctness by generating random input tensors and comparing the outputs of the optimized kernels against the corresponding PyTorch operators. Since all operators produce float32 outputs, we used PyTorch’s standard relative (rtol) and absolute (atol) tolerances to account for minor numerical differences.
In addition, we benchmarked execution time in milliseconds (ms) and power draw (watts) against both PyTorch native execution and torch.compile. For each configuration, benchmarks were run for 1,000 iterations to minimize system noise and obtain stable, reliable performance measurements. We conducted testing and benchmark on the NVIDIA H100 GPU. Below are our results:
RmsNorm
SiLU
rotate_half
Each optimized kernel significantly outperforms the PyTorch operator in both native and torch.compile modes while maintaining identical power draw. The speedup comes from eliminating framework overhead, enforcing contiguous memory access, and executing the entire operation in a single, specialized kernel with minimal dispatch and control logic.
In contrast, torch.compile can be slower than native PyTorch for small or already-optimized, memory-bound kernels, where compilation overhead and limited fusion opportunities outweigh its benefits. Its strength is on large graph fusion, not microkernels.
After validating functional correctness and benchmarking all optimized kernels, we fine-tune both the baseline and optimized QWEN3 models on real-world data from Nemotron-Post-Training-Dataset-v2, focusing on mathematics and programming tasks. During training, we measure tokens per second at each iteration to capture end-to-end speedups, including forward, backward, and optimizer steps. After fine-tuning, we evaluate both model variants on standard benchmarks—HumanEval, Competition Math, LiveCodeBench, and AIME 2025—to compare accuracy. Below, we report the configurations and performance results of the optimized model versus the baseline.
Configurations :
Model: Qwen/Qwen3-4B-Instruct-2507
Dataset: nvidia/Nemotron-Post-Training-Dataset-v2 (split: math,code)
Max Train Samples: 1000
Batch Size: 2 (per device)
Gradient Accumulation: 2
Max Length: 8192
Learning Rate: 2e-5
Precision: bfloat16
Hardware: NVIDIA H100 GPU
Software :
CUDA : 13.0
Pytorch : 2.10
Transformers : 4.57
Results :
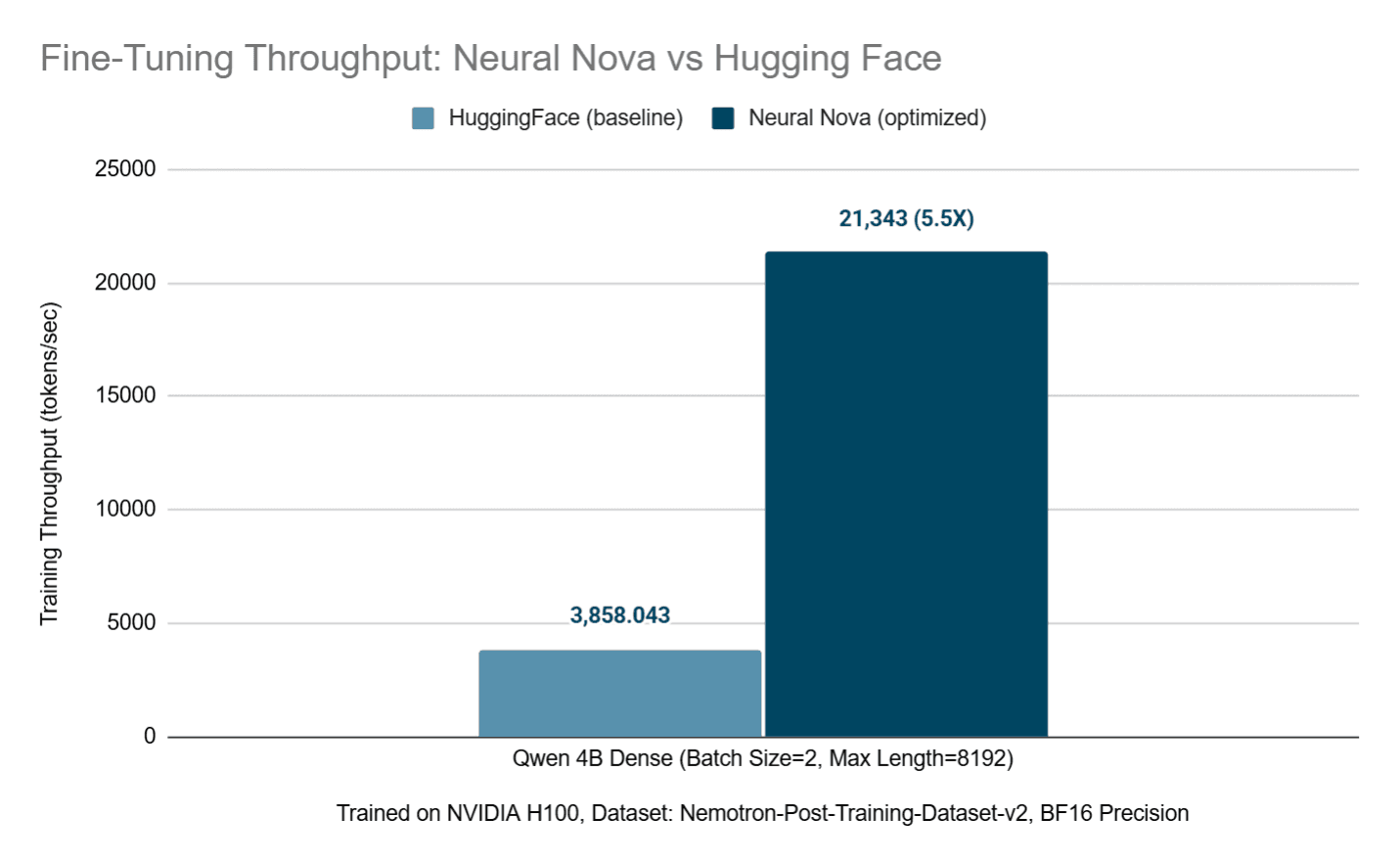
Overall, the optimized QWEN3 model delivers a ~5.5× throughput improvement over the baseline (21,343 vs. 3,858 tokens/sec) while preserving evaluation accuracy across all benchmarks, demonstrating that kernel-level optimizations translate into substantial end-to-end training speedups on real-world workloads.
Integration with LLaMA-Factory Training Framework
To demonstrate seamless integration with modern LLM ecosystems, Neural Nova’s optimized kernels were deployed within the LLaMA-Factory fine-tuning framework. LLaMA-Factory is a popular choice for structured Supervised Fine-Tuning (SFT), and this experiment validates that Neural Nova’s low-level optimizations are fully compatible with high-level orchestration tools.
The Neural Nova kernels act as drop-in replacements for standard Transformers operators. When using LLaMA-Factory for Full SFT, the framework's standard training loop—including gradient accumulation and data loading—remains untouched. The performance gains are realized simply by substituting the model's internal layers with Nova-optimized variants.
LLaMA-Factory Configuration
Model: Qwen/Qwen3-4B-Instruct-2507
Stage: SFT
Finetuning Type: Full
Dataset: nvidia/Nemotron-Post-Training-Dataset-v2 (split: math,code)
Max Train Samples: 1000
Batch Size: 1 (per device)
Gradient Accumulation: 1
Max Length: 8192
Learning Rate: 2e-5
BF16 Mixed Precision : False
Testing within the LLaMA-Factory environment showed that eliminating framework-level operator overhead leads to a massive reduction in iteration time. Even when constrained by the framework's internal management logic, Neural Nova delivers a 3.5× throughput improvement
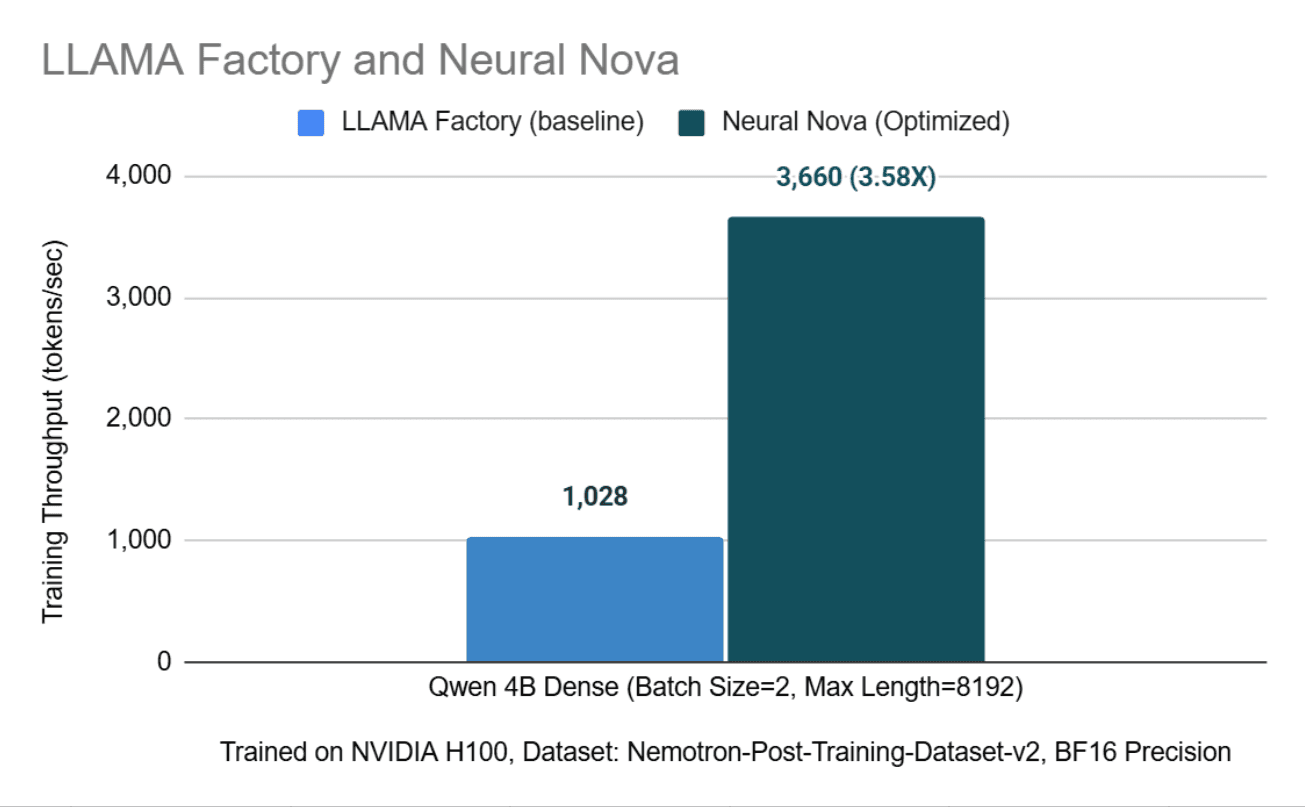
This demonstrates that Neural Nova effectively bypasses the performance bottlenecks typically encountered when scaling models within high-level training frameworks, providing a direct path to faster iteration cycles for fine-tuning workloads.
We additionally evaluate Neural Nova’s effectiveness in multi-GPU fine-tuning scenarios. Specifically, we fine-tune the Qwen 3 32B model using four GPUs, holding the dataset and training framework constant via LLaMA Factory.
Through this controlled setup, we measure throughput before and after applying Neural Nova’s optimization stack. The observed fine-tuning throughput is summarized below:
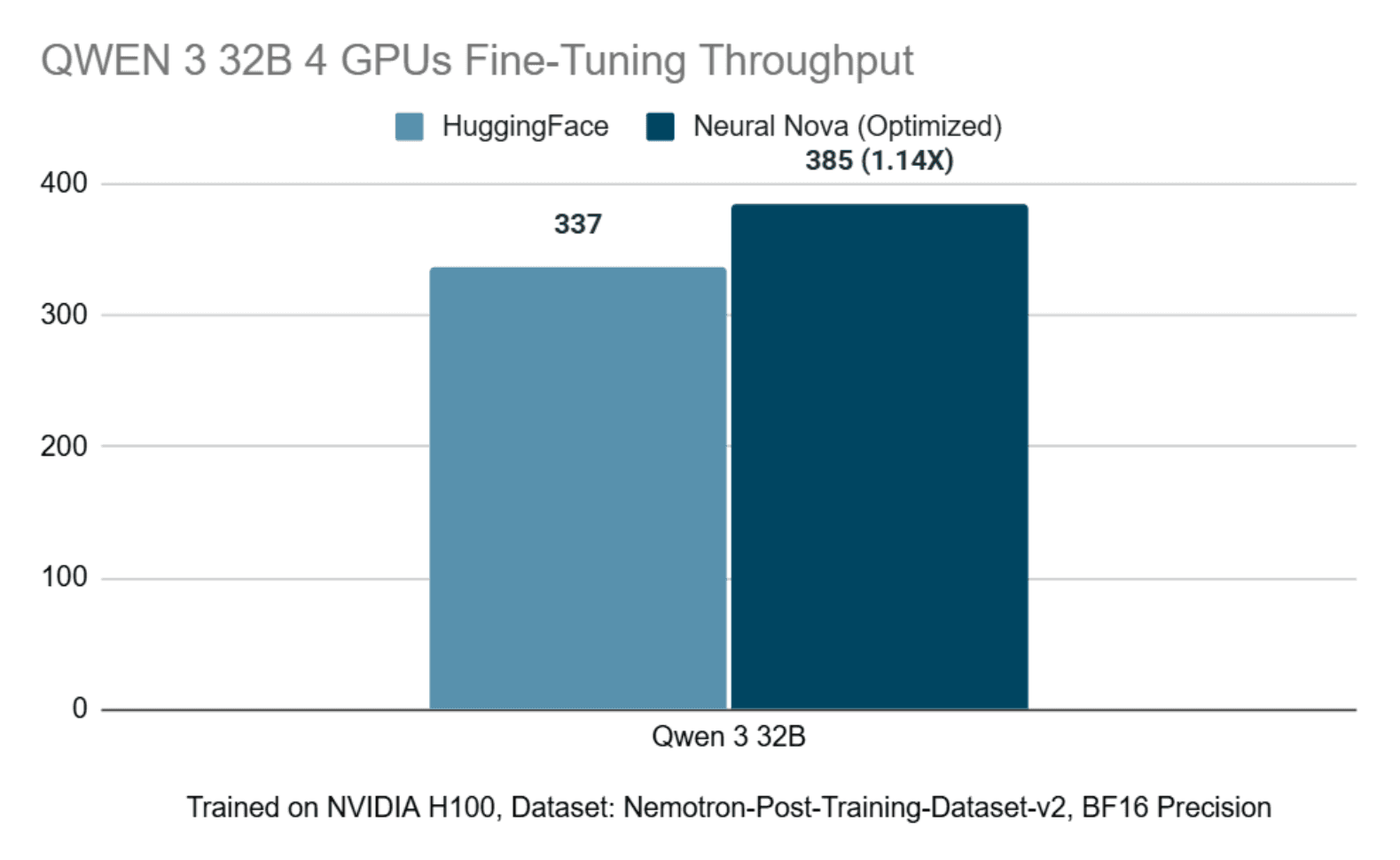
These results demonstrate that Neural Nova maintains effective performance characteristics in multi-GPU configurations. The Nova AI Engine systematically optimizes execution behavior in distributed settings, validating its applicability beyond single-GPU fine-tuning and into scaled training workloads.
Next we investigate the accuracy of the QWEN3 models to perform mathematics and programming tests.
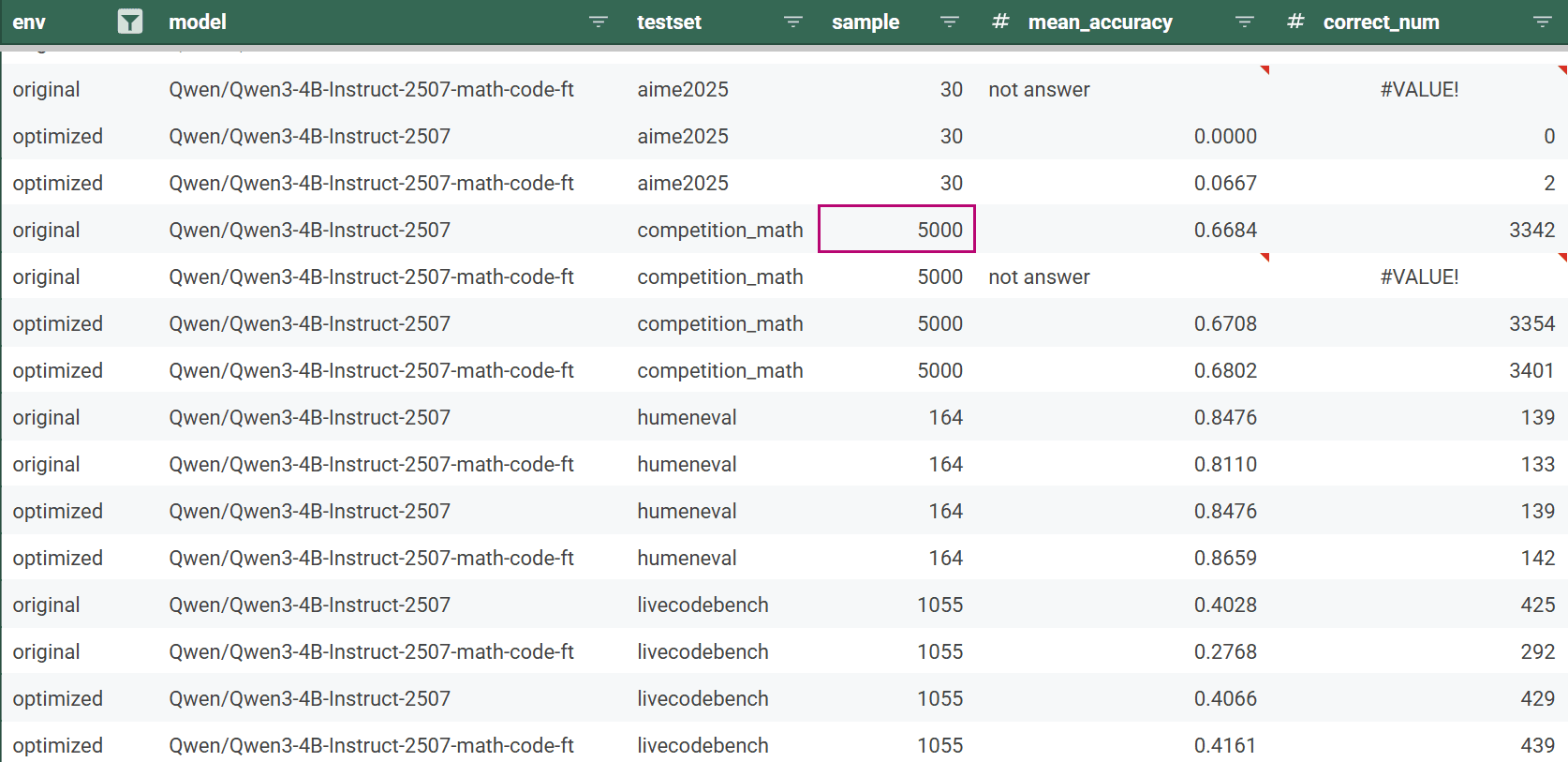
Overall, this blog demonstrates how Neural Nova delivers substantial end-to-end performance gains by systematically optimizing model execution at the operator level without altering model architecture, training logic, or numerical semantics. Using the Qwen-3 4B model fine-tuned on a single NVIDIA H100 GPU, Neural Nova automatically identifies performance-critical operators and generates hardware-efficient CUDA kernels for RMSNorm, Rotate Half, and SiLU. These optimized kernels outperform both native PyTorch and torch.compile while maintaining numerical correctness and identical power draw. When integrated into the full training pipeline, the optimizations translate into a 5.5× increase in fine-tuning throughput (21,343 vs. 3,858 tokens/sec) with no loss in evaluation accuracy, demonstrating that operator-level optimization can unlock real-world training speedups beyond the reach of graph-level compilers for memory- and synchronization-bound workloads.