
Menu
Accelerating Qwen3-4B Fine-Tuning by 56%

Fine-tuning large language models is expensive. As teams iterate on datasets, prompts, evaluation sets, and model variants, GPU time quickly becomes one of the largest costs in the development cycle. The usual answer is to add more GPUs. But in many cases, the faster path is to improve how efficiently the training workload runs on the GPUs already available.
At Neural Nova AI, we recently optimized a Qwen3-4B fine-tuning workload on both H100 and A100 environments. On 1× NVIDIA H100, we improved training throughput from 6,214.93 tokens/sec to 9,665.23 tokens/sec, a 1.555× speedup, or +55.5% higher fine-tuning throughput. On 1× NVIDIA A100-SXM4-40GB, we improved throughput from 1,540 tokens/sec to 2,409 tokens/sec, a 1.564× speedup, or +56.4% higher fine-tuning throughput.
Both results were achieved without changing the model architecture, fine-tuning objective, or dataset. The model was Qwen/Qwen3-4B-Instruct-2507, the non-thinking instruction variant of Qwen3-4B. The H100 benchmark used a Hopper-aware stack with FlashAttention-3, while the A100 benchmark used CUDA 12.8 with FlashAttention-2.
Headline Result
The fine-tuning benchmark used full fine-tuning with bf16, sequence length 4096, packing enabled, gradient checkpointing enabled, batch size 1, gradient accumulation 4, and one epoch on a math subset of the Nemotron post-training dataset.
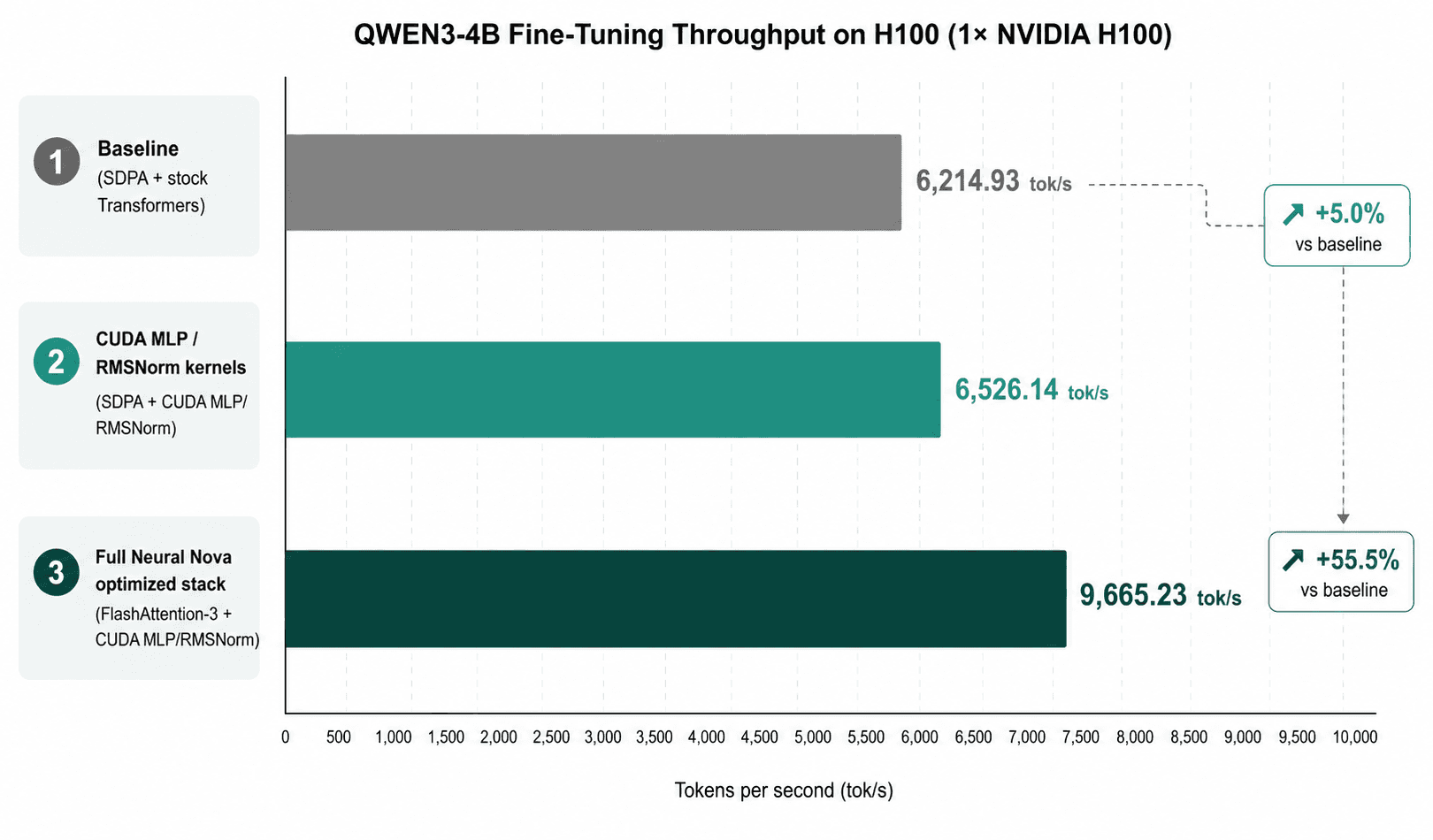
On H100, the baseline stack used stock Transformers with SDPA attention. We updated the optimized stack to use FlashAttention-3, which is better aligned with Hopper GPUs. This improved throughput from 6,214.93 tokens/sec to 9,665.23 tokens/sec, a 1.555× speedup.
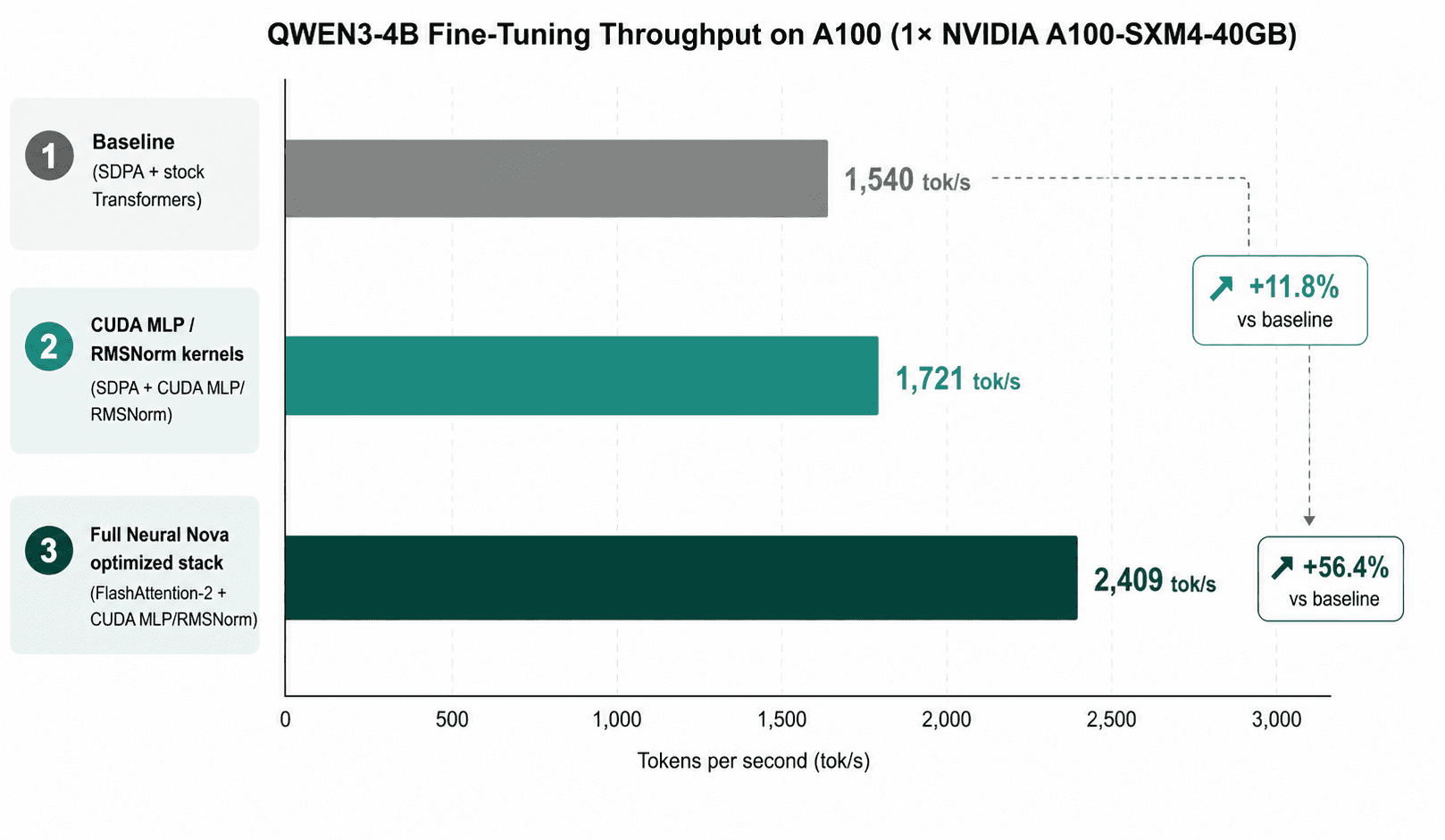
On A100, the optimized stack used a patched Transformers environment with FlashAttention-2 and customized CUDA forward/backward kernels for MLP and RMSNorm. This improved throughput from 1,540 tokens/sec to 2,409 tokens/sec, a 1.564× speedup.
The full optimized stack delivered similar relative gains on both A100 and H100. This is especially meaningful because the workload used long packed sequences with max_length=4096. Long, dense training batches are exactly where attention efficiency, memory movement, and fused GPU execution can have an outsized impact.
What Changed in the Training Stack
The model and training objective stayed the same. The optimization happened at the execution layer.
The baseline used:
Stock Transformers
SDPA attention
Stock MLP execution
Stock RMSNorm execution
The optimized H100 setup used:
Patched Transformers
FlashAttention-3
Optimized CUDA forward/backward kernels for MLP
Optimized CUDA forward/backward kernels for RMSNorm
The optimized A100 setup used:
Patched Transformers
FlashAttention-2
Optimized CUDA forward/backward kernels for MLP
Optimized CUDA forward/backward kernels for RMSNorm
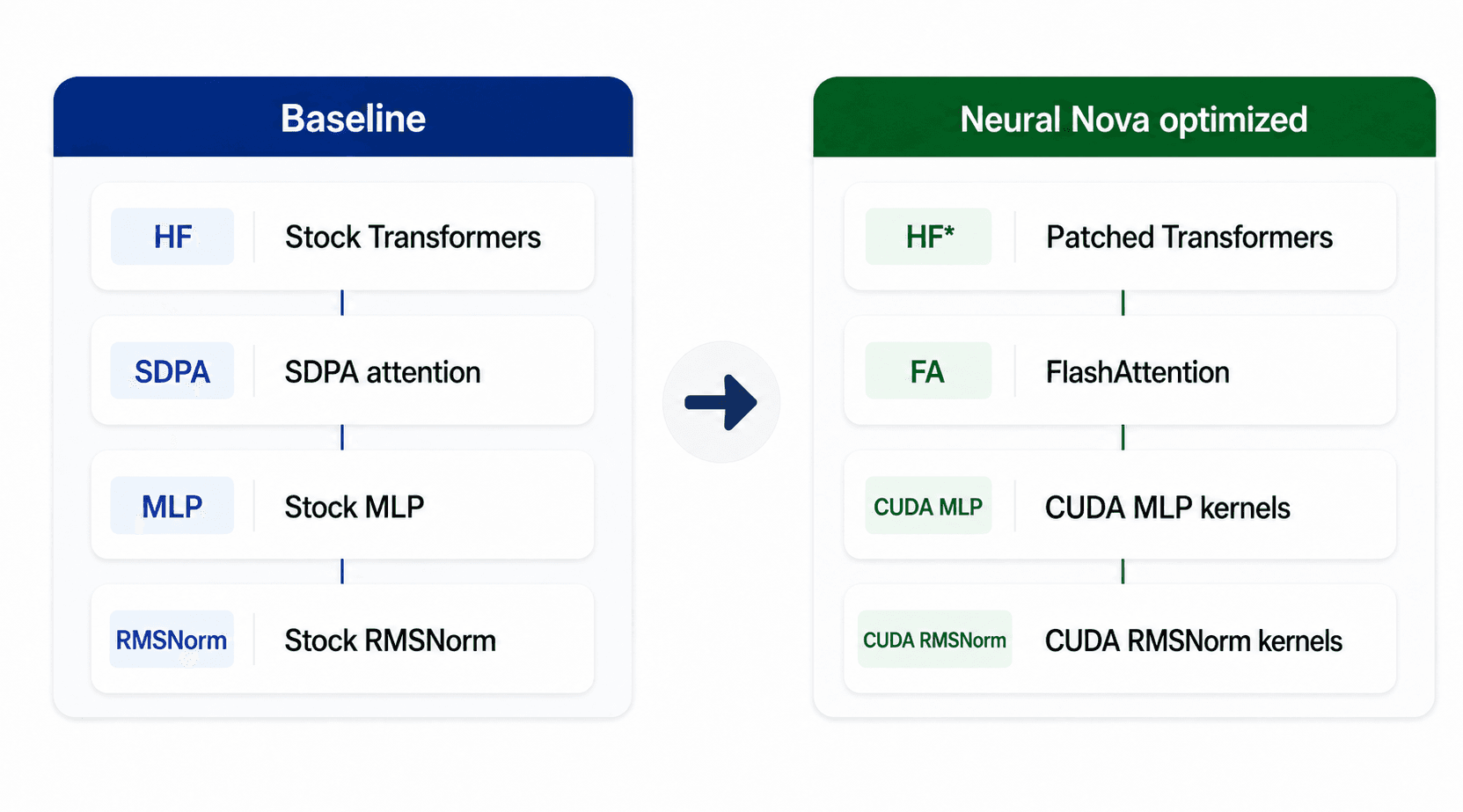
This is important because the improvement did not come from reducing the workload or changing the model behavior. It came from making the same training workload execute more efficiently on the target GPU. The right attention backend also depends on the hardware: FlashAttention-2 was used for the A100 result, while FlashAttention-3 unlocked the larger Hopper-specific gain on H100.
H100 Contribution Breakdown: CUDA Kernels vs FlashAttention-3
We first tested the Qwen3-4B fine-tuning workload on a single NVIDIA H100. Because H100 is based on the Hopper architecture, the optimized stack used FlashAttention-3 instead of FlashAttention-2.
Configuration | Throughput | Gain vs Baseline |
|---|---|---|
Baseline: SDPA + stock Transformers | 6,214.93 tok/s | 1.00× |
CUDA kernels only: SDPA + CUDA MLP/RMSNorm | ~6,526 tok/s | ~1.05× |
Full optimized stack: FA3 + CUDA MLP/RMSNorm | 9,665.23 tok/s | 1.555× |
On H100, the CUDA MLP/RMSNorm kernels alone contributed roughly 5% throughput improvement. The larger unlock came from using FlashAttention-3, which is better aligned with Hopper GPUs. With FA3 and the custom CUDA kernels together, the optimized stack reached 9,665.23 tokens/sec, or 1.555× baseline throughput.
This shows why fine-tuning optimization should be treated as a hardware-aware full-stack systems problem. Kernel-level improvements matter, but attention implementation, GPU architecture, sequence length, packing behavior, memory access patterns, and framework integration all interact.
A100 Contribution Breakdown: CUDA Kernels vs FlashAttention-2
We also tested the same Qwen3-4B fine-tuning workload on a single NVIDIA A100. For A100, the optimized stack used FlashAttention-2 together with the same custom CUDA MLP and RMSNorm kernels.
Configuration | Throughput | Gain vs Baseline |
|---|---|---|
Baseline: SDPA + stock Transformers | 1,540 tok/s | 1.00× |
CUDA kernels only: SDPA + CUDA MLP/RMSNorm | 1,721 tok/s | ~1.12× |
Full optimized stack: FA2 + CUDA MLP/RMSNorm | 2,409 tok/s | 1.564× |
On A100, the CUDA MLP/RMSNorm kernels alone improved throughput by about 12%. FlashAttention-2 on top of those kernels drove the larger combined speedup, bringing the final optimized result to 2,409 tokens/sec, or 1.564× baseline throughput.
Together, the H100 and A100 results reinforce the same pattern: optimizing one layer helps, but optimizing the execution path together can produce a much larger gain. The right attention backend also depends on the GPU architecture. FA3 was the right fit for H100, while FA2 was the right fit for A100.
Correctness and Validation
Performance improvements are only useful if the training process remains valid. We validated the optimized fine-tuning run in several ways. First, both baseline and optimized runs updated the expected model weights during full fine-tuning. Weight-change verification confirmed that attention projections and MLP projections were updated in both runs. Second, GSM8K evaluation remained within expected variance for the 50-sample evaluation setup. The benchmark showed that accuracy differences were within the expected sampling noise range, and output lengths remained similar.
Post-Finetune Accuracy — GSM8K
Evaluation: 50 samples, 4-shot CoT
Fine-tuned on: nvidia/Nemotron-Post-Training-Dataset-v2 math subset, 10%, 100 samples, 1 epoch, full fine-tune
Config: Same as fine-tuning performance benchmark
Metric | Finetuned Baseline | Finetuned Optimized | Pre-finetune Baseline | Pre-finetune Optimized |
|---|---|---|---|---|
Accuracy | 0.96 | 0.94 | 0.94 | 0.96 |
Avg throughput | 25.58 | 38.32 | 25.42 | 37.69 |
Avg latency / req | 9.614 | 6.455 | 11.239 | 7.524 |
Avg output tokens | 245.94 | 247.38 | 285.72 | 283.56 |
Third, the optimized stack did not change the fine-tuning objective or model architecture. The goal was to improve execution efficiency, not to alter the training task. The small accuracy difference is within expected variance for a 50-sample GSM8K evaluation and should not be interpreted as a statistically meaningful regression.
Weight Change Verification — Layer 13, Full Fine-Tune
Projection | Baseline vs Base | Optimized vs Base | Baseline vs Optimized |
|---|---|---|---|
| CHANGED | CHANGED | DIFFER |
| CHANGED | CHANGED | DIFFER |
| CHANGED | CHANGED | DIFFER |
| CHANGED | CHANGED | DIFFER |
| CHANGED | CHANGED | DIFFER |
| CHANGED | CHANGED | DIFFER |
| CHANGED | CHANGED | DIFFER |
The key point: the optimized run improved throughput while preserving expected training behavior.
Business Impact: Lower Fine-Tuning Cost and More GPU Capacity
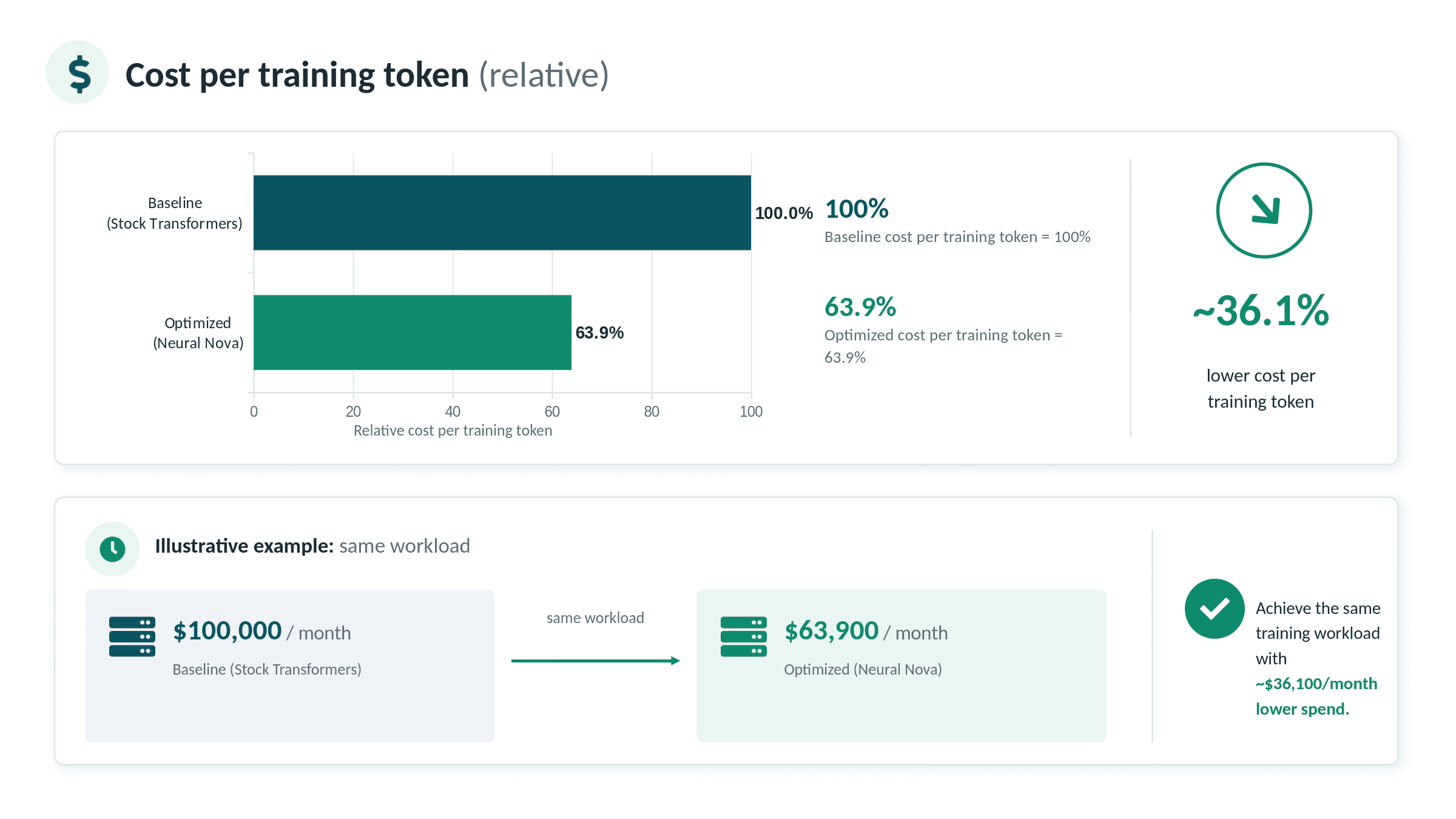
Fine-tuning throughput is not only an engineering metric. It directly affects cost, capacity, and iteration speed. In this benchmark, Neural Nova improved Qwen3-4B fine-tuning throughput from 1,540 tokens/sec to 2,409 tokens/sec, a 1.564× speedup. That means the same A100 can process more training tokens per hour. Assuming the same GPU-hour cost, utilization rate, and workload shape, the cost per training token decreases by approximately:
In cost terms, that translates to approximately 36.1% lower compute cost per training token. In practical terms, a workload that previously required 100 GPU-hours could require roughly 64 GPU-hours under the optimized throughput profile. A larger workload that previously required 50,000 GPU-hours could require approximately 31,969 GPU-hours, freeing up about 18,031 GPU-hours for additional experiments or other workloads.
Baseline Monthly Fine-Tuning Spend | Equivalent Optimized Spend | Estimated Monthly Savings |
|---|---|---|
$100,000 | $63,900 | $36,100 |
$250,000 | $159,800 | $90,200 |
$500,000 | $319,500 | $180,500 |
$1,000,000 | $639,400 | $360,600 |
The H100 result shows a similar pattern. Neural Nova improved Qwen3-4B fine-tuning throughput from 6,214.93 tokens/sec to 9,665.23 tokens/sec, a 1.555× speedup. Under the same assumptions, that corresponds to approximately 35.7% lower compute cost per training token.
For teams running repeated fine-tuning jobs, this compounds quickly. The same GPU budget can support more experiments, faster dataset iteration, shorter training cycles, and more model variants without immediately increasing infrastructure spend. This is especially important for teams fine-tuning models frequently across different datasets, customer domains, languages, evaluation sets, or product use cases.
The exact savings depend on GPU cost, utilization rate, training configuration, and workload mix. But the relationship is straightforward: when training tokens per second increase on the same infrastructure, cost per training token decreases.
How Neural Nova Helps
Neural Nova AI helps teams improve fine-tuning and inference performance on their existing GPU infrastructure. We profile the current workload, identify bottlenecks, optimize the execution path, validate model integrity, and measure before/after performance under representative conditions.
For customers, this can mean:
Lower cost per training run
Faster fine-tuning and experiment cycles
Higher tokens/sec for inference workloads
Lower inference latency
Better GPU utilization
More capacity from the same infrastructure
Lower cost per token
Our work can include:
Attention optimization
CUDA kernel optimization
Framework-level integration
Training and inference throughput profiling
Memory and runtime bottleneck analysis
Model integrity checks
Cost-per-token and cost-per-training-run analysis
The goal is simple: help customers fine-tune and serve models faster without redesigning their model, changing their dataset, or rebuilding their production pipeline. If your team is running fine-tuning or inference workloads and wants to improve performance per GPU, contact us to explore a benchmark with Neural Nova AI.
Conclusion
In this Qwen3-4B fine-tuning benchmark, Neural Nova improved training throughput by approximately 56% on both NVIDIA H100 and A100 single-GPU environments. On H100, throughput increased from 6,214.93 tokens/sec to 9,665.23 tokens/sec, a 1.555× speedup. On A100, throughput increased from 1,540 tokens/sec to 2,409 tokens/sec, a 1.564× speedup.
The optimized stack combined hardware-aware attention optimization with custom CUDA MLP and RMSNorm kernels inside a patched Transformers environment. For H100, FlashAttention-3 unlocked the larger Hopper-specific gain. For A100, FlashAttention-2 was the right fit. In both cases, the model architecture, dataset, and fine-tuning objective stayed the same.
The broader lesson is clear: fine-tuning performance is not only a model problem or a GPU problem. It is a systems problem. For teams running fine-tuning workloads at scale, optimizing the execution layer can mean faster iteration, lower cost per experiment, and more training capacity from the infrastructure they already have. Neural Nova AI helps teams unlock that performance headroom across fine-tuning, inference, and production AI workloads.